1 系统原理
为了解决传统的基于误用的入侵检测系统只能检测已知攻击,不能检测未知攻击以及已知攻击变种的缺陷,目前常用的解决方法是把数据挖掘分析方法应用到入侵检测领域,构建基于这些分析方法的入侵检测系统。通常入侵检测可以看作是一个模式识别问题,即根据网络流量特征(目的地址、源地址、目的端口号、源端口号、传输协议、发送字节数、TCP选项等)和附加属性特征(连接时间、连接频度、数据长度、数据负载均值和方差等)来判别区分对系统访问的正常行为和异常行为,这是一个典型的分类问题。在训练样本为不均衡的未标定数据集时,入侵检测问题又可视为一个孤立点发现或样本密度论问题。数据挖掘为解决这类问题提供了大量的方法,如关联分析、序列分析、分类、聚类分析、孤立点分析以及基于粗糙集的挖掘。
分类算法虽然已经相当成熟,但是他不能有效的适应动态环境变化,而粗糙集算法的计算复杂性也限制了它在入侵检测系统中的应用。因此本文综合使用孤立点挖掘、异常检测和关联分析技术来构建自适应的网络入侵检测模型。
1.1. 孤立点挖掘在异常检测中的应用
异常检测,也称为基于行为的入侵检测,以系统、网络、用户或进程的正常行为建立轮廓模型,将与之偏离较大的行为解释成入侵。基于异常的入侵检测技术有一个假设,就是入侵和滥用行为不同于一般正常用户或者系统的行为。异常检测先在用户、系统或者网络正常操作的一段时间内收集事件和行为的信息,再根据这些信息建立正常或者有效的行为模式。在检测的时候,通过某种度量,计算事件行为偏离正常行为的程度。把当前行为和正常模式比较,如果偏离程度超过一定的范围,则报警异常。
1.1.1. 异常检测中的孤立点挖掘算法
孤立点挖掘是数据挖掘技术中一个重要的研究方向,从大量复杂的数据中挖掘出隐藏于小部分异常数据中的与常规数据模式显著不同的数据模式。
孤立点的挖掘可以描述如下:给定一个n个数据点或对象的集合,及预期的孤立点的数目k,发现与剩余的数据相比是显著相异的前k个对象。孤立点挖掘可以看作是两个子问题:(1)在给定的数据集合中定义什么样的数据可以被认为是不一致的;(2)找到一个有效的方法来挖掘这样的孤立点。
本文使用改进的基于相似系数和的孤立点检测算法[12][18],描述如下:
设论域
 (1)
(1)
现在的目标是求出n个对象的孤立点集合。
为了判断X中各对象的离散程度,先计算各对象两两之间的相似系数,并构成相似系数矩阵,即
 (2)
(2) 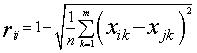 (3)
(3) ![]() (4)
(4)
其中, 是相似系数矩阵第i行的和,该值越小,就说明对象i与其他对象的距离越远,即为孤立点集的候选项。
![]() (5)
(5)
其中,![]() 为阈值,满足
为阈值,满足![]() ≥
≥![]() 的对象则被认为是孤立点。
的对象则被认为是孤立点。
1.1.2. 基于入侵检测的孤立点挖掘算法描述
入侵检测对孤立点挖掘算法的基本要求是时效性和准确性,而上述算法的复杂度为O(n2),如果直接用于实时入侵检测系统,则会严重影响入侵检测的实时性,因此需要对上述孤立点挖掘算法做实时性改进处理;同时又由于网络数据的动态变化,所以本文使用基于定长动态滑动窗口的孤立点挖掘算法,窗口长度为固定的数据包个数w,而滑动长度的单位为i个数据包,这样新的i个数据包到达时,窗口向前滑动一个单位长度,而只需要更新R矩阵的1到i列,其它值保持不变即可,故孤立点挖掘的时间复杂度为O(n)。
(责任编辑:adminadmin2008)





