改进的算法描述如下:
输入:向量化的经过预处理的入侵检测数据记录
输出:入侵检测异常数据包(孤立点集)
方法:
1) 对于新的经过预处理的数据包
2) 对于每个新的数据包按照公式(3)计算p到前w-1个包的相似系数,更新相似系数矩阵R
3) 重新计算每一行相似系数的和pi
4) 按照公式(5)计算每个包的偏离度
5) 输出满足条件
数据的预处理主要是使各特征属性的值在区间[0,1]内。预处理主要包括数据的标准化和正规化处理,分别入公式(6),(7):
 (6)
(6) 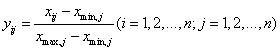 (7)
(7)
其中![]() ,
,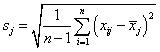 分别是x的第j维的一个特征属性的均值和标准偏差。经过标准化变换(6)和正规化处理(7)后,各特征属性的均值为0,方差为1。
分别是x的第j维的一个特征属性的均值和标准偏差。经过标准化变换(6)和正规化处理(7)后,各特征属性的均值为0,方差为1。
注意上述算法中,偏离度阈值 对孤立点挖掘的质量有着直接的影响, 如果较低的话,会导致输入较大的误检率。而 较高会导致较高的漏检率,实际使用中偏向于较高的 ,这样会在运行初期有较高的漏检率,但是随着系统的运行,使用下述的自适应算法,使得系统能够自反馈的学习已检测孤立点属性的潜在关联,进而能够逐渐降低漏检率。
1.2. 构建自适应入侵检测的原理描述
传统的入侵检测方法首先针对已知的训练集进行训练,得出一个检测模型,然后基于这个检测模型来判断新的数据是否为入侵活动。显然从某个环境中收集数据建立的检测模型不可能很好地应用于其它环境的系统,这意味着为了建立一个良好的检测模型需要从多个不同的环境中收集数据,并且覆盖所有不同的环境,显然这样是极不可取的。因此需要建立自适应的入侵检测方法,让入侵检测系统能够随着环境的变化,不断自我学习,不断改变自己的检测策略,来识别未知入侵行为。
在使用孤立点挖掘技术识别出网络活动的异常行为的孤立点后,由于存在各种各样的攻击形式,如果直接对这些杂乱的孤立点进行关联分析,不仅使关联分析算法中的阈值设置困难,而且关联分析的结果对网络异常数据包的检测作用也不明显。因此本文先对挖掘出的孤立点按照攻击类型进行聚类,然后对聚类结果中的每个类进行关联分析,挖掘出各种攻击网络异常数据包中潜在的入侵行为模式,产生相应的关联规则集,再转换成具体入侵检测系统的规则语法,并添加到规则库中[15]共入侵检测引擎使用,从而达到入侵检测的自适应。
1.2.1. 基于改进的Apriori关联规则挖掘算法
由R.Agrawal等人提出的Apriori算法是经典的关联规则挖掘算法。该算法将关联规则的发现分为两步:
(1) 找出所有的频繁项集,即项集出现的频度不小于用户预先设定的最小支持度。
(2) 从频繁项集产生强关联规则,即构造置信度不低于用户给定的最小置信度的关联规则,同时满足最小支持度和最小置信度的规则。
但由于Apriori在构建过程中并没有考虑到性能优化问题,可能会产生大量的候选集,需要多次重复扫描数据库,基于此,本文使用了基于Apriori的改进算法AprioriTid[13],来进行关联规则挖掘。算法AprioriTid的基本思想是基于减少扫描事物量:如果一个事物不包含k 阶大项集,那么也必然不包含k+1 阶大项集,因此,将这些事物删除后,下一次循环中就可以减少扫描的事物量,而不会影响候选项集的支持数。具体说来,AprioriTid 算法采用Apriori_gen 运算产生候选项集之后,构造一个Tid表,用来记录每条事物包含的候选项集。
AprioriTid 算法的过程描述如下:

AprioriTid 算法的优势在于用逐渐减小的Tid 表代替原来的事物数据库,从而减少了扫描事务的数量,随着候选项集的显著减少,AprioriTid 算法效率上的优越性就体现出来了。
(责任编辑:adminadmin2008)





